
Introduction
Access Generative AI model APIs at 80% lower cost
MonsterAPI is an AI computing platform designed to help developers build Generative AI-powered applications using no-code and cost-effective tooling.
The platform is powered by a state-of-the-art ingenious Decentralised GPU cloud built from the ground up to serve machine learning workloads in the most affordable and scalable way.
MonsterAPI Capabilities:
- Access pre-hosted Generative AI APIs
- Finetune Large Language Models (LLMs)
- Deploy Open-source and Finetuned LLMs
Let’s explore each of these solutions in detail:
Access Generative AI Model APIs:
MonsterAPI offers a variety of state-of-the-art AI models, including:
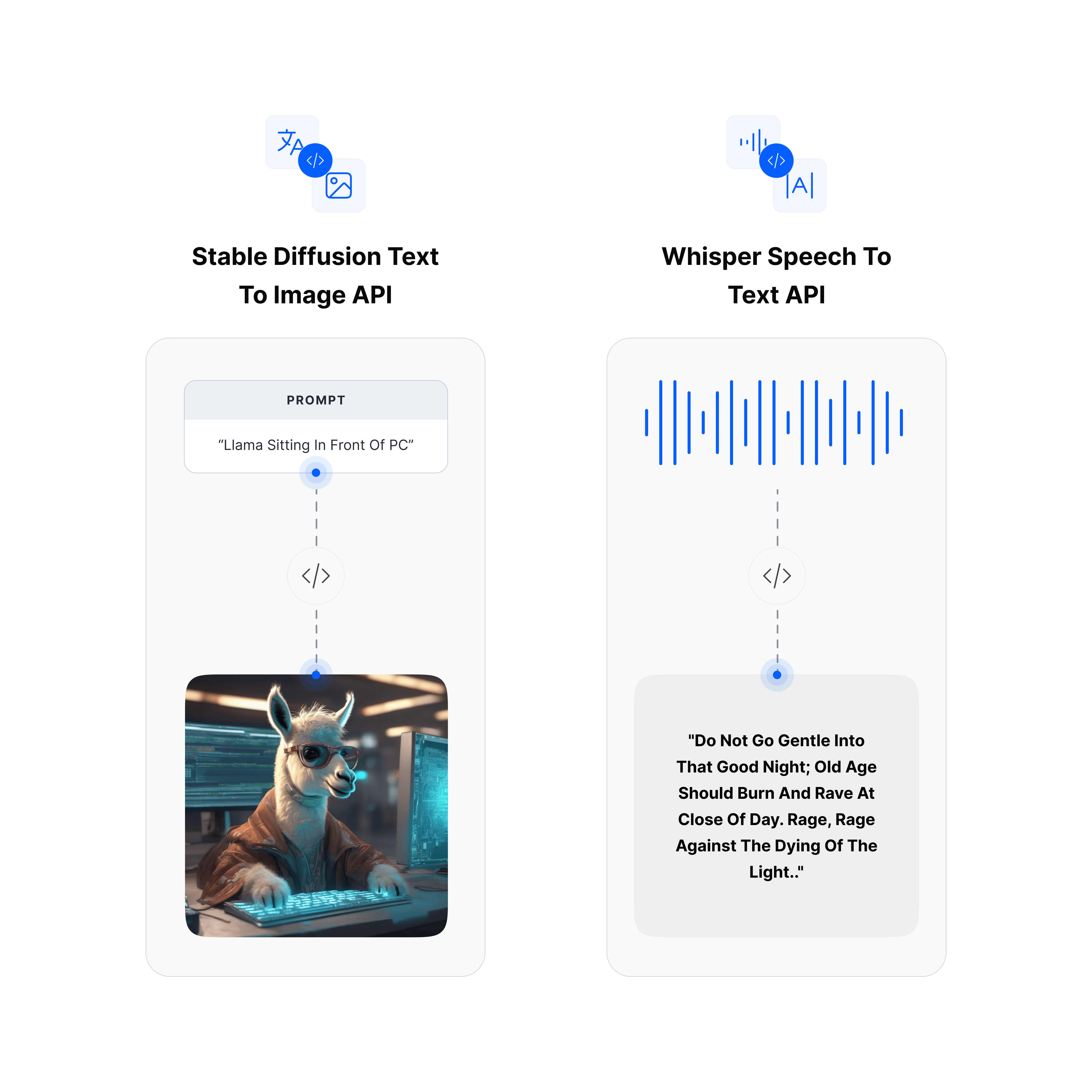
- Stable Diffusion XL (SDXL) for Image Generation
- Whisper Large-v2 for Speech to text Transcription
- Gemma2, Mistral 7B, Llama3, Phi3, and more LLMs for high-quality text generation.
We optimize these Generative AI models and host them on our scalable GPU cloud as ready-to-use API endpoints that can be accessed via our cURL, PyPI, and NodeJS clients. This enables developers to easily build AI-powered applications while getting access to AI models at up to 80% lower cost than other alternatives.
MonsterTuner - No-code Large Language Model Finetuning:
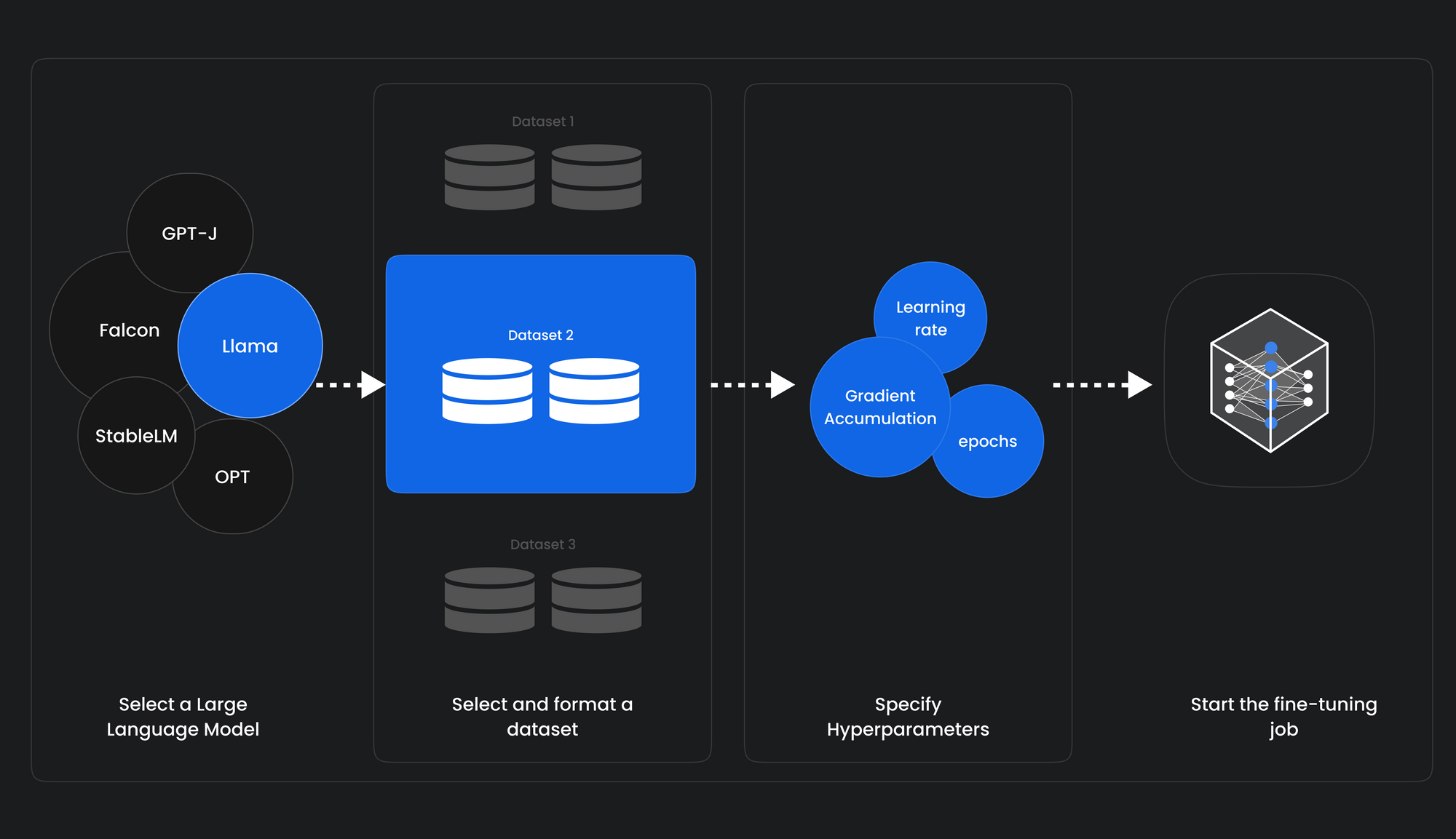
MonsterTuner is a no-code large language model (LLM) finetuner that simplifies the complex process of finetuning and customizing AI models on your datasets, reducing the process to 4 simple steps:
- Select an LLM - Gemma, Mistral, Llama, Phi, and many more supported.
- Select a Huggingface Dataset or use your own custom datasets.
- Specify hyperparameters or use our pre-baked templates.
- Review and launch finetuning job.
Benefits of No-Code Finetuning with Monster Tuner:
- Automatic batch size configuration
- Automatic GPU server configuration with an appropriate computing environment
- Automatically addresses issues like Out of Memory (OOM)
- In-built support for avoiding overfitting with parameters like early stopping
- In-built support for tracking experiments with WandB.
This results in a smooth, standardized, and cost-optimized LLM finetuning process, built for your business use-case requirements. Check out our detailed developer docs on LLM fine-tuning.
MonsterDeploy - Deploy Large Language Models (LLMs):
MonsterDeploy is a serving engine designed for seamless deployment of Large language models (LLMs) and docker containers on MonsterAPI's robust and low-cost GPU cloud.
Supported Solutions:
- Deploy open-source pre-trained and fine-tuned LLMs as a REST API endpoint.
- Deploy docker containers for application workflows.
MonsterDeploy automatically configures the GPU infrastructure and manages it to ensure smooth access to the hosted models. Once the deployment is live, you can query your hosted LLMs and fetch the generated output.
Key capabilities of MonsterDeploy:
- Effortless Model Compatibility: Deploy any vLLM compatible model with ease.
- Flexible Scaling: Scale up to 4 GPUs with adaptable GPU RAM sizes within your budget.
- One-Click Deployment: Launch LLM deployments smoothly with a single command.
- Diverse Model Support: Support for various models and LoRa-compatible adapters like Gemma2, LLaMA-3, Mistral, Phi and more.
With MonsterDeploy, the deployment of LLMs becomes a straightforward and cost-effective process, enabling you to focus on innovation rather than complex deployment logistics. Check out our developer docs for deploying LLMs on MonsterAPI.
MonsterAPI is committed to democratizing the use of Generative AI models by developing solutions that are affordable, easy to use, and scalable, thus reducing the effort and skill set needed to build a Generative AI-powered application.
Updated about 1 year ago