
For LLM Fine-tuning
To prepare a Dataset for Fine-tuning a Large Language Model (LLM), below are the various supported methods:
- Augment existing Datasets
- Synthesize Instruction Datasets
- Upload your Custom Datasets
- Use a HuggingFace Dataset
Below are detailed guides for each supported method:
1. Augment your existing Datasets
The Data Augmentation Service enables users to expand their datasets by generating additional data rows based on existing data or creating a new preference dataset. This service is particularly useful for model fine-tuning, leading to better performance by introducing more varied data.
You can specify details about the data to be augmented, including source type and data split, and choose between two tasks: generating evolved instructions or generating preference datasets.
Due to OpenAI token generation Rate limits, right now the service is available to models with > 400,000 TPM. accessible through Tier 2 and above accounts.
The following steps are involved in creating an augmented dataset:
- First, pick the dataset you want to augment, then create an OpenAI API key and MonsterAPI access token:
OPENAI_KEY = 'YOUR_API_KEY'
MONSTERAPI_KEY = 'YOUR_API_KEY'
hf_dataset_id = '<hf_dataset>'
dataset_split_to_use = 'test'
- Load the dataset and visualize it.
dataset = datasets.load_dataset(hf_dataset_id)
df = pd.DataFrame(dataset[dataset_split_to_use])
df.head()
By visualizing the dataset, we can see which column contains the prompt.
- We can post a request to the API to augment the dataset, like below:
body = {
"data_config": {
"data_path": f"{hf_dataset_id}",
"data_subset": None,
"prompt_column_name": "prompt",
"data_source_type": "hub_link",
"split": f"{dataset_split_to_use}"
},
"task": "evol_instruct",
"generate_model1_name": "gpt-3.5-turbo",
"generate_model2_name": "gpt-3.5-turbo",
"judge_model_name": "gpt-3.5-turbo",
"num_evolutions": 4,
"openai_api_key": f"{OPENAI_KEY}"
}
headers = {'Authorization': f'Bearer {MONSTERAPI_KEY}'}
response = requests.post('https://api.monsterapi.ai/v1/generate/data-augmentation-service', json=body, headers=headers)
if response.status_code != 200:
print(response.json())
raise ValueError('Failed to send request', response.json())
process_id = response.json()['process_id']
- We can check the status of the job by running the following cell:
# lets check the status of the process
def check_status(process_id):
response = requests.get(f"https://api.monsterapi.ai/v1/status/{process_id}", headers=headers)
return response.json()['status']
# wait for it to show 'COMPLETED'
status = check_status(process_id)
while status != 'COMPLETED':
status = check_status(process_id)
if status == 'FAILED':
print('Process failed, Try again!')
raise ValueError('Process failed')
print(f"Process status: {check_status(process_id)}")
time.sleep(10)
# lets get the results
response = requests.get(f"https://api.monsterapi.ai/v1/status/{process_id}", headers=headers)
results = response.json()['result']
output_path = results['output'][0]
print('Output path:', output_path)
- Once the process is completed we can download the augmented dataset as follows:
output_ds = datasets.load_dataset('csv',data_files=output_path)
pd.DataFrame(output_ds['train']).head()
2. Synthesize instruction datasets
The potential of supervised multitask learning, particularly in the post-training phase, cannot be overlooked. This method has shown promising results in enhancing model generalization. In a groundbreaking paper, researchers have introduced a novel framework called Instruction Pre-Training, which aims to elevate language model pre-training by integrating instruction-response pairs into the learning process.
With the Synthesizer API, users can effortlessly generate their own instruction-response datasets. This service leverages the instruction synthesizer model to create datasets suitable for both instruction pre-training and instruction fine-tuning, simplifying the process significantly. This no-code solution spares users from the laborious tasks of data scraping and running a language model locally. Additionally, it offers substantial cost savings, generating labeled datasets at a fraction of the cost compared to models like GPT and Claude.
To generate an instruction-response dataset, all you need is a corpus in a hugging face dataset format. Make Sure your corpus is available as manageable chunks in a column named ‘text’.
You can call the instruction synthesizer with the following steps:
- Setup the base_url to the API’s base url as follows:
url = "https://api.monsterapi.ai/v1/deploy/instruction-synthesizer"
- Once this is set up, you can simply post a request as follows:
payload = {
"model_name": "instruction-pretrain/instruction-synthesizer",
"temperature": 0,
"max_tokens": 400,
"batch_size": 2,
"seed": 42,
"input_dataset_name": "<INPUT DATASET PATH>(For example: RaagulQB/quantum-field-theory)",
"output_dataset_name": "<OUTPUT DATASET PATH>(For example: RaagulQB/quantum-field-theory-instruct)",
"hf_token": "<HF TOKEN>"
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <MONSTER API TOKEN>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
- Input_dataset_name: name of the hf dataset to use
- Output_dataset_name: name of the dataset to be uploaded to huggingface
- Hf_token: A valid Hugging face token with write permission.
If you don’t have a proper dataset, you can refer to following colab notebook that explains how you can create a dataset out of a PDF file: ![]()
3. Custom Dataset: Using your own dataset
- Select Task Type: Click on the dropdown menu and choose the type of task you are training for, such as text classification, summarization, or question-answering.
- Choose Dataset Source: Click on the Choose Dataset dropdown menu. You have two options here:

- Select Your Dataset: Choose the Custom Dataset you have uploaded in the Datasets section. Make sure your dataset is in one of the supported formats: JSON, JSONL, CSV, or Parquet.
- Configure Hyperparameters: Set the appropriate hyperparameters based on your dataset's structure, and then proceed to the next step.
Click 'Next' to finalize your fine-tuning job request. Our FineTuner will then handle the remaining steps with precision and efficiency.
4. Using Hugging Face Datasets:
-
Select Task Type: Follow the same step as above to select the task type.
-
Choose Dataset Source: Set the dataset source to "Hugging Face Datasets."

-
Select the Dataset: Choose a dataset from the Hugging Face list or provide the path to a specific Hugging Face dataset by selecting "Other" and entering the dataset's path.
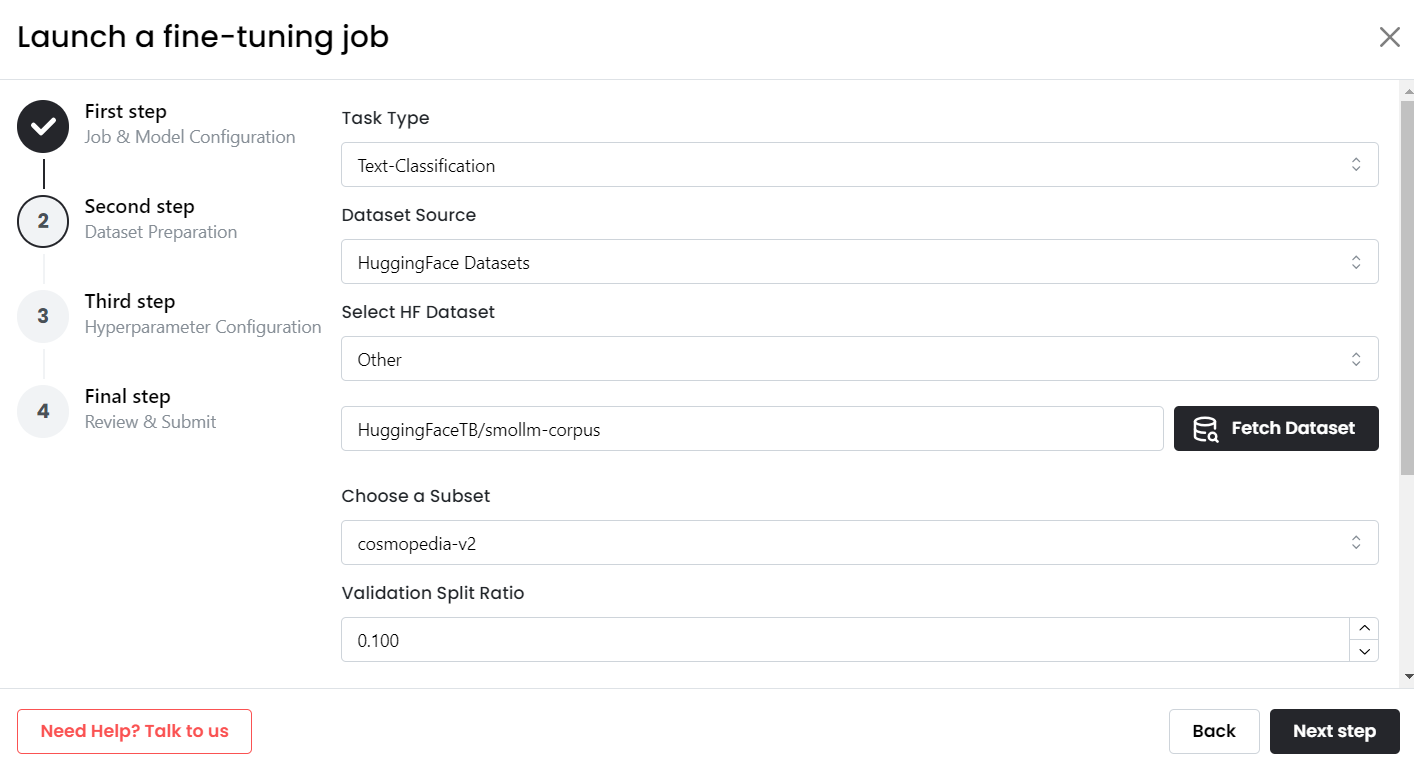
- Choose the Subset: If the dataset has multiple subsets, select the one you want to use. If no subsets are available, the dataset will default to the full version.
Prompt Configuration
Upon selecting a dataset, you'll find a section labeled 'Prompt Configuration.' This section should be adjusted according to the specifics of your selected dataset.
- For Custom Datasets: Replace placeholders in the prompt configuration section with the actual column names in your dataset.
- For HuggingFace Dataset: Replace the placeholders inside the square brackets with the actual column names from your dataset that you wish to use for fine-tuning.
If you have a pre-curated HuggingFace Dataset then no dataset prompt configuration is required as it is pre-filled and you can simply click on "Next" and proceed ahead.
For example, if your dataset has columns like prompt, response, and source, you will replace:
{replace with instruction column name}withpromptand{replace with response column name}withresponse.
After making these changes, your updated data preparation window looks like this:
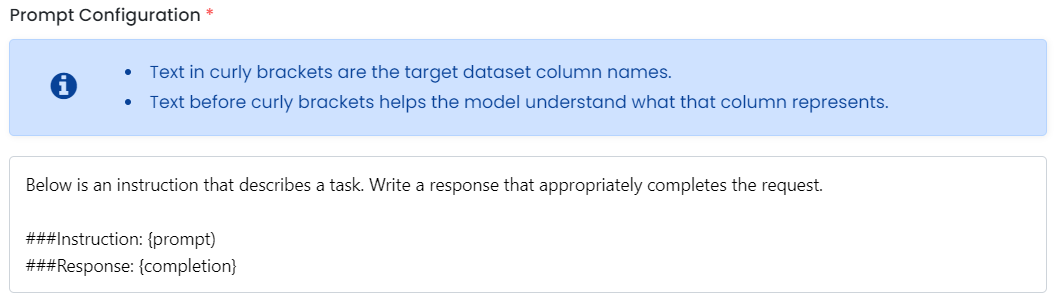
And we are done!! Click 'Next' to finalize your fine-tuning job request. Our FineTuner will then handle the remaining steps with precision and efficiency.
Updated 12 months ago