
Launch a LLM Finetuning Job
This guide walks you through the process of fine-tuning a large language model using MonsterTuner - a no code scalable LLM fine-tuner
Pre-requisites
Before proceeding further, please ensure that the following conditions are met:
- Have a valid MonsterAPI account - Don't have an account? Sign up.
- Minimum 1,000 API credits required - Haven't purchased yet? Explore our plans.
- After logging into your account, open the "Fine-Tuning" Portal from left side menu.
- Then click on the "Create New Job" button.
Now you are all set to follow the steps for crafting and launching an LLM finetuning job.
Step by step guide:
-
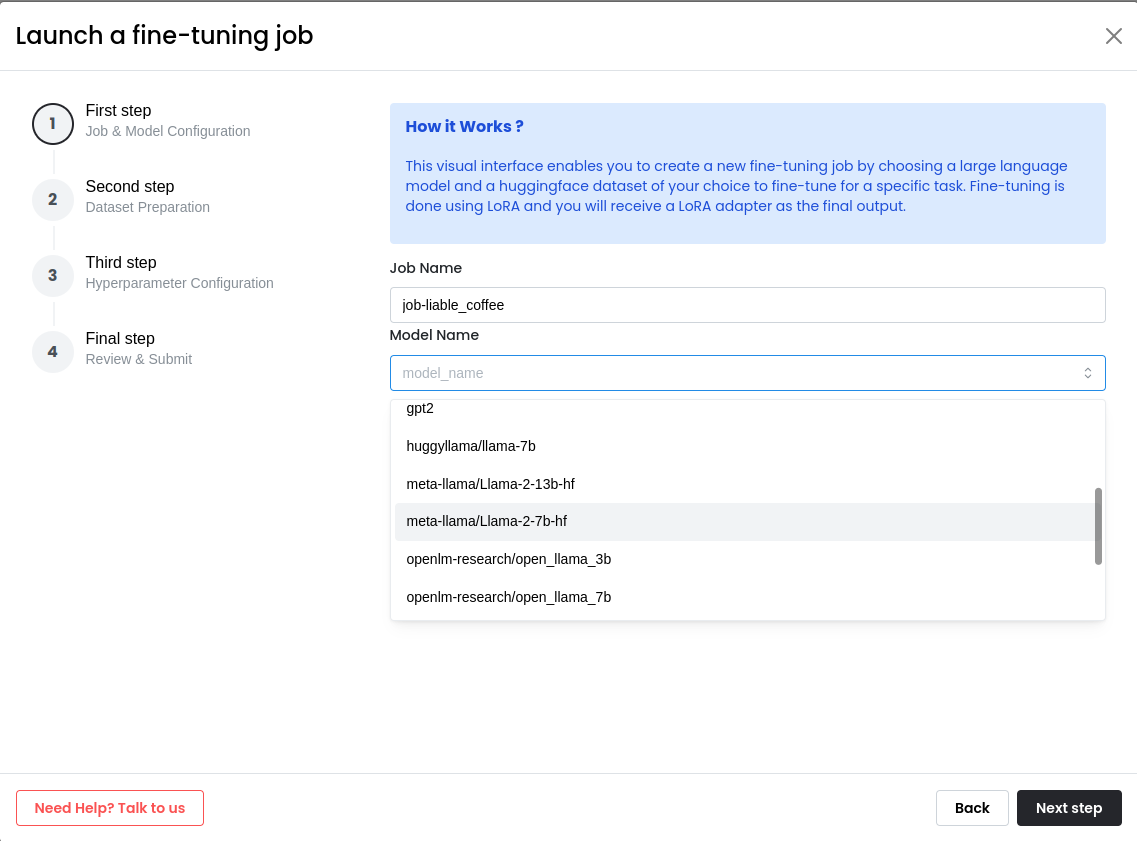
Specify Job Name and Select an LLM
Specify a unique job name and select an LLM model from the drop-down menu based on your use-case.
You can choose from the latest Large Language Models (LLMs) such as Llama 2 7B, CodeLlama, Falcon, GPT-J 6B or X-Gen.
-
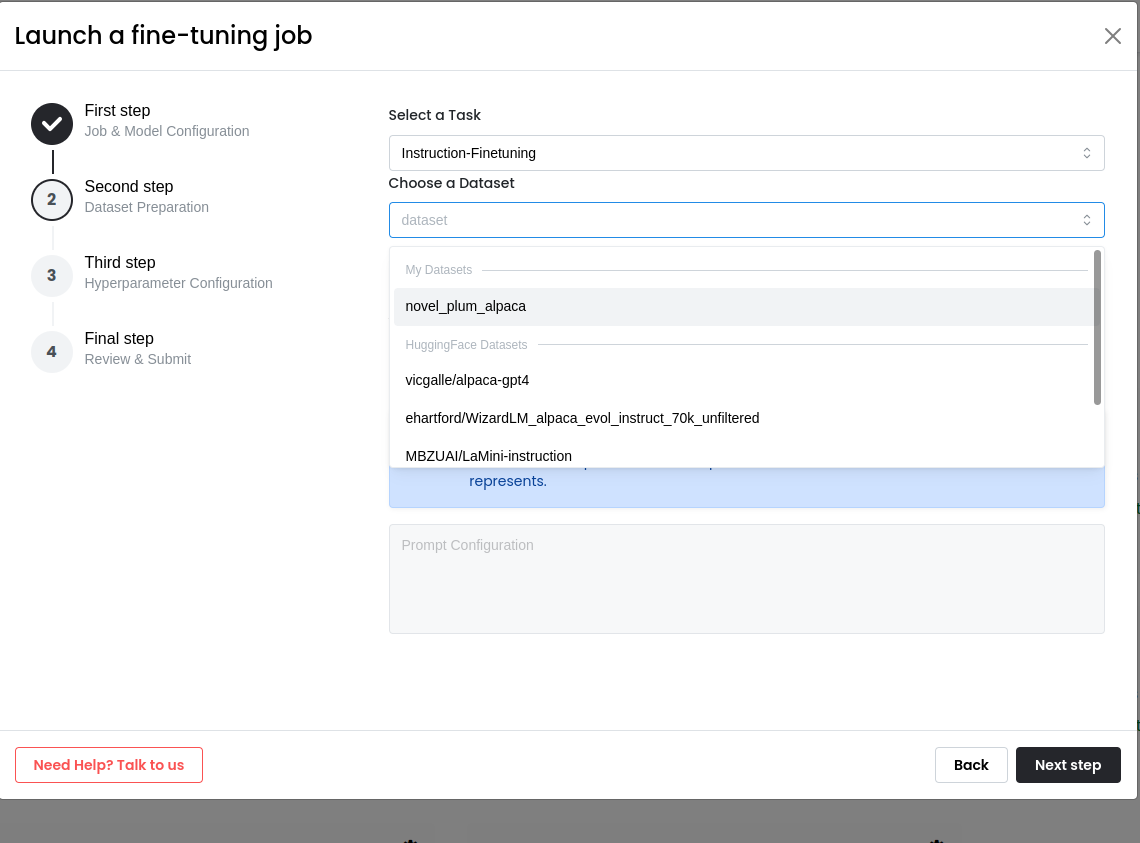
Select a Task and Dataset
Select a Fine-Tuning Task:
Select a task for fine-tuning the LLM. This could be "Instruction Fine-Tuning", "Text Classification", or any other task of your choice. If your task is not listed, select the "Other" option and specify your custom task and update the below prompt configuration to match the task at hand.Select a Dataset:
While selecting a dataset to be used for finetuning, user has three options:Option 1 - Select a curated Hugging Face Dataset:
Choose from our curated selection of mostly used hugging face datasets with predefined training prompt configuration. If the chosen dataset has subsets they can be selected from the 'choose a Subset' dropdown. This dropdown becomes visible after you have chosen a particular dataset.
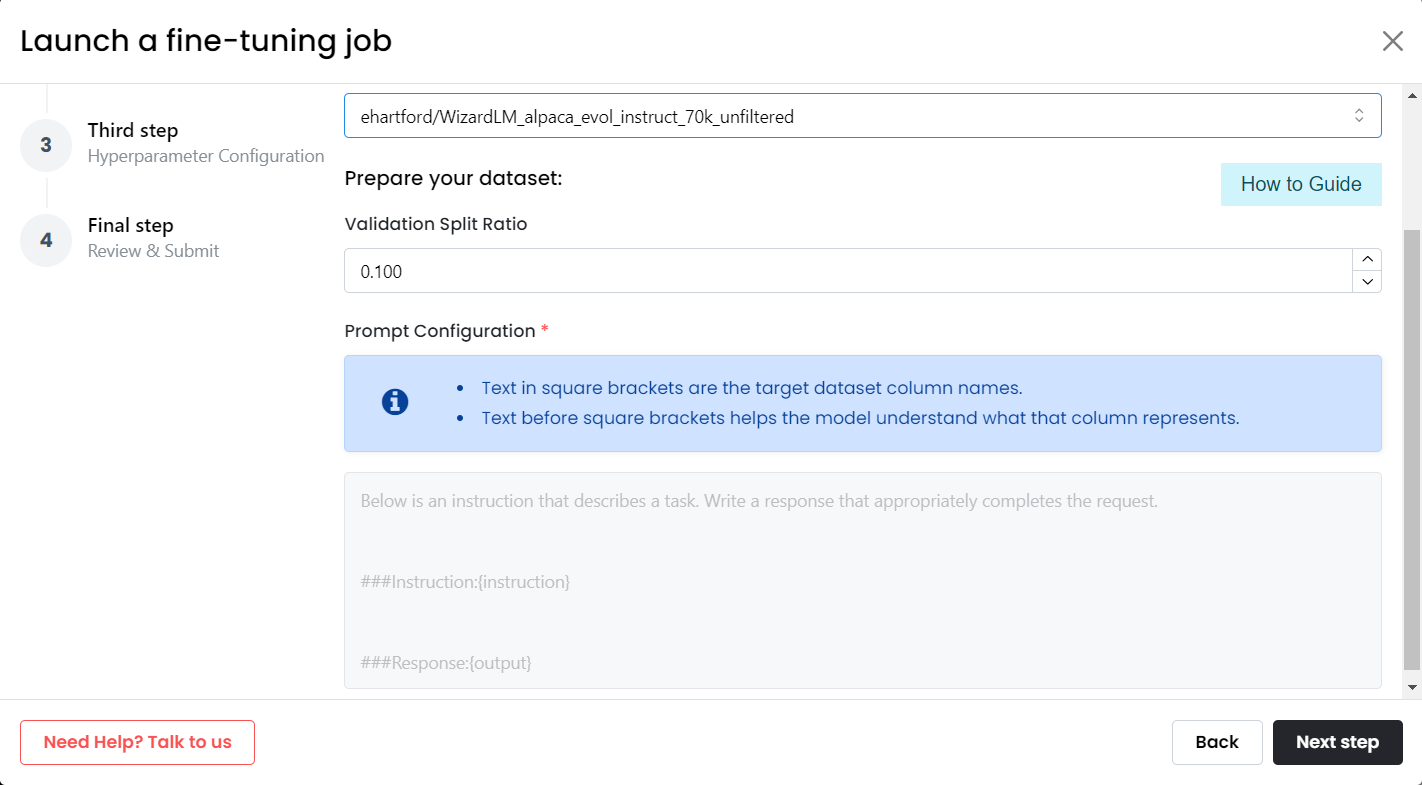
Option 2 - Use any other unlisted Hugging Face Dataset:
If you are unable to find a Hugging Face dataset of your choice in our curated list then you may choose 'other' option and provide dataset name for the Hugging Face dataset to fetch and use.
If the Hugging Face dataset has subsets enabled you can choose the subset from choose a Subset dropdown. if the dataset has no subsets, default subset is automatically selected.
Unlike the case of pre-curated datasets, you'd now have to specify the Prompt Configuration in below text section to replace the relevant column names in square brackets with appropriate column names in the dataset.
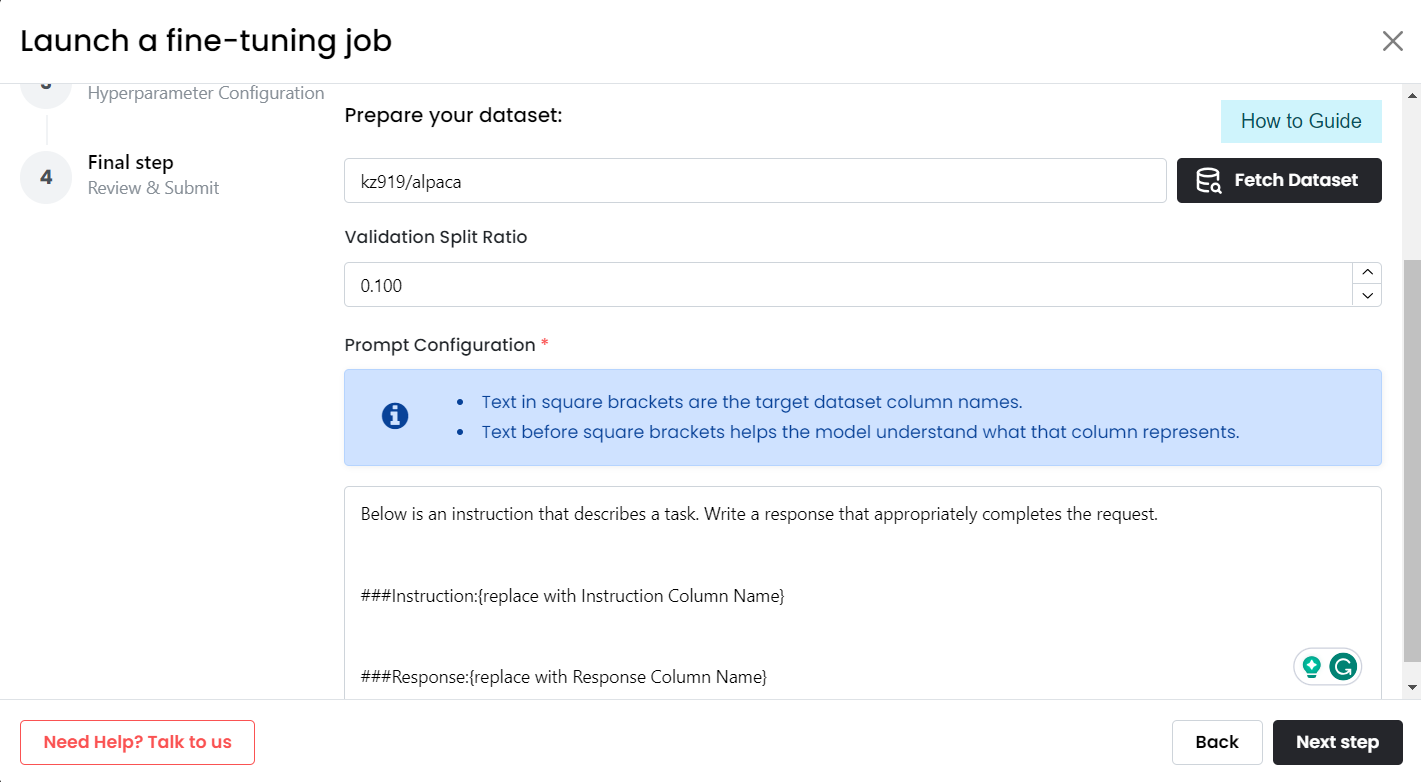
Prompt Configuration Example: If kz919/alpaca dataset is fetched through 'other' option.
We replace suggested prompt:
###Instruction:{replace with Instruction Column Name}
###Response:{replace with Response Column Name}
as follows:
###Instruction:{prompt}
###Response:{completion}
prompt and completion are the appropriate column names in our example dataset.
Option 3 - Select your Custom Dataset:
You can use your datasets for finetuning as well.
Custom Datasets
Refer to our documentation on Custom Datasets for details on how to upload and use a custom dataset.
If you have already uploaded a dataset to MonsterAPI platform via "Dataset management" portal, then you will be able to choose your dataset from "My Datasets" dropdown section. This section will appear automatically only if you have already uploaded datasets.
Unlike the case of pre-curated datasets, you'd now have to specify the Prompt Configuration in below text section to replace the relevant column names in square brackets with appropriate column names in your dataset.
Example:
Let us say we uploaded a dataset named as novel_plum_alpaca which is a csv file with 2 columns in it, named as "prompt" and "completion".
When we select this dataset from My Datasets dropdown, we are displayed a Text Area named as "Prompt Configuration". We need to specify our target column names in that configuration to help the finetuner use our dataset properly for finetuning.
We replace the default prompt configuration:
###Instruction:{replace with Instruction Column Name}
###Response:{replace with Response Column Name}
with this:
###Instruction:{prompt}
###Response:{completion}
since 'prompt' is the instruction column in our dataset and 'completion' is the response column name in our dataset.
-
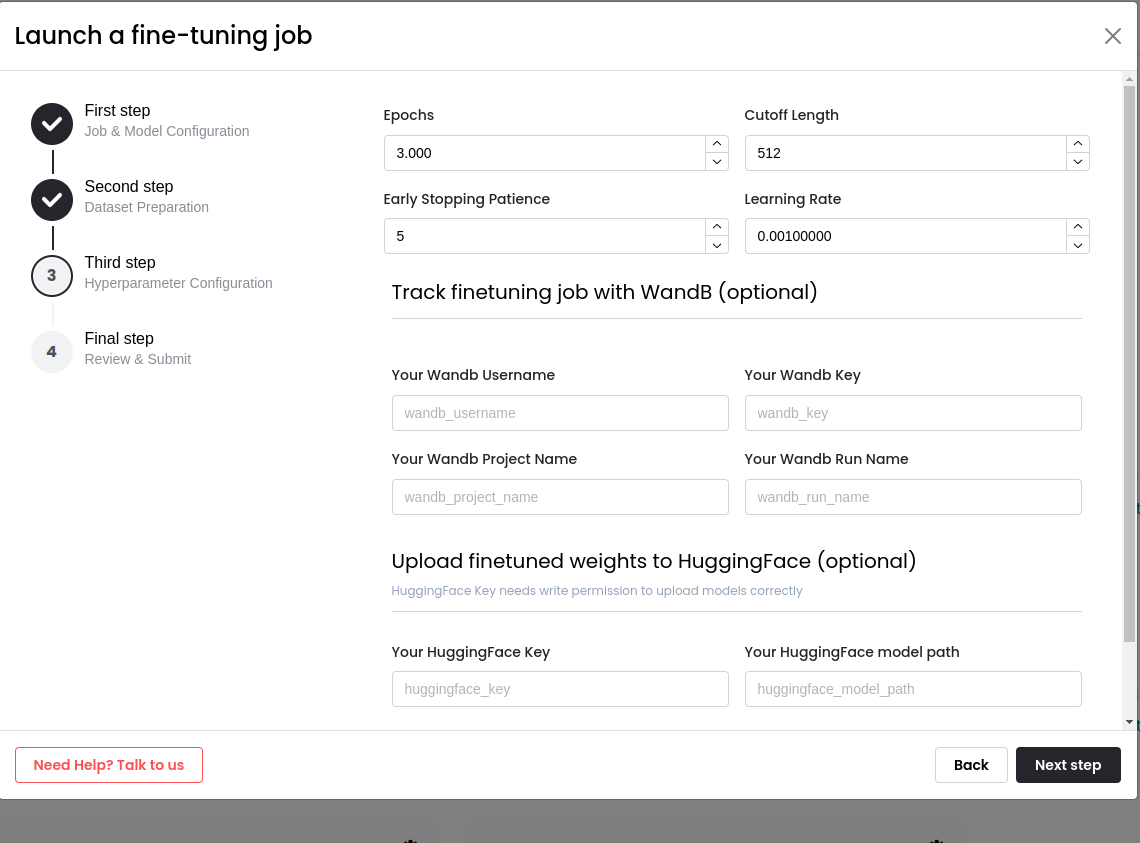
Specify Hyperparameter Configuration
In this step, set your hyper-parameters such as epochs, learning rate, cutoff length, warmup steps, and so on. These parameters are automatically filled based on your chosen model, but you can modify them according to your needs.
HuggingFace and WandB credentials can be provided to upload the model into HuggingFace and record training logs into WandB.
Please note: These parameters affect the fine-tuning process and can also lead to failure if not set correctly.
Please Note
The cutoff len option is an internal mechanism at the dataset level for the batch-size finding and speed optimization.
The final model's context length will solely dependent on the pretrained base model used and cutoff len parameter is independent from it
For example, if the pretrained base model used is LLaMA2 7b which supports a context length of 4096. Then the output finetuned model will also support 4096, Irrespective of what the value of cut off length was set to
-
Finally, Review and Submit Job
Click on Next to proceed to the summary page.
Review the final job summary to ensure all the settings are correct, then submit your request.
That's it! Your finetuning job starts in a couple of minutes and when it switches to IN PROGRESS state, you would be able to view the job logs and metrics (see next section for setting up metrics tracking using WandB).
⚙️ Optional Settings
-
Track your Fine-Tuning job using WandB:
To track your fine-tuning run, you may add your WandB credentials on Third step:
- Your WandB username
- Your WandB key (you can get your WandB key here)
- Your project name (go to WandB and create a project if you don't have already)
- Your WandB run name (could be any random name of your choice)
If you add these valid credentials, the job will automatically start sending metrics to your WandB project so you can track the progress in your experiments.
-
Upload model outputs to Huggingface Repo:
If you want to store the final fine-tuned model weights in a HuggingFace repository, add your HuggingFace credentials on Third step:
- Your Huggingface API Key (Must have write access)
- Your Huggingface Repo Path
If you add these credentials, the job will automatically publish the fine-tuned weights to your huggingface repo upon completion.
That's it! Finished!
Updated 12 months ago