
Boosting LLM Performance with Unsloth and SDPA Integration 🚀
We're thrilled to unveil two major upgrades to MonsterTuner, designed to supercharge your LLM fine-tuning: Unsloth and Scaled Dot-Product Attention (SDPA). These innovations bring significant enhancements in performance, efficiency, and context length.
Unsloth Integration:
Unsloth eliminates inefficiencies and redundancies, delivering over 100% performance improvement during fine-tuning.
In our benchmark tests, Unsloth-optimized models completed tasks in just 40 seconds compared to 87 seconds for non-Unsloth variants.
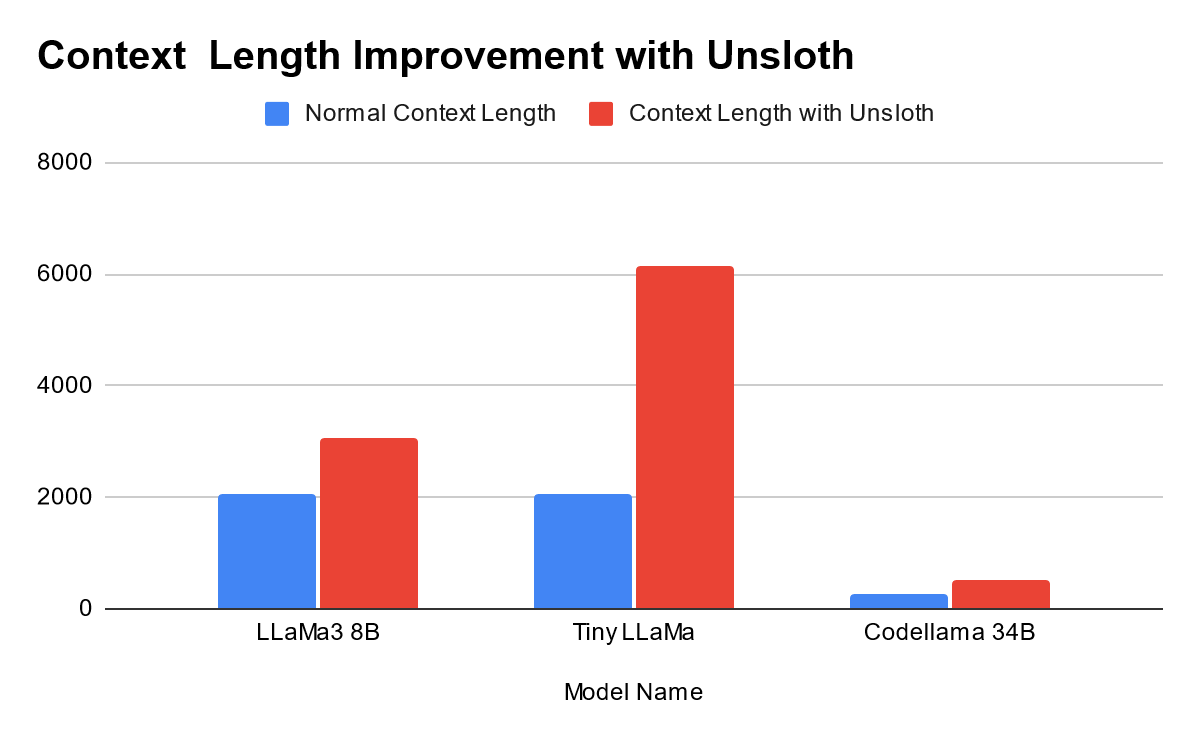
Performance Highlights:
-
LLaMa3 8B:
- Normal context length: 2048
- With Unsloth: 3072
-
Tiny LLaMa:
- Normal context length: 2048
- With Unsloth: 6144
-
Codellama 34B:
- Normal context length: 256
- With Unsloth: 512
SDPA Integration:
SDPA enhances model focus, efficiency, and scalability by computing scaled attention scores, dynamically improving context and relationships in data.
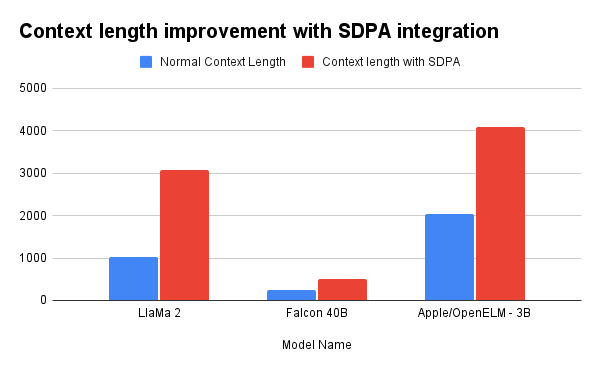
Performance Highlights:
-
LLaMa 2:
- Without SDPA: 1024
- With SDPA: 3072
-
Falcon 40B:
- Without SDPA: 256
- With SDPA: 512
-
Apple/OpenELM-3B:
- Without SDPA: 2048
- With SDPA: 4096
Key Benefits of using Unsloth and SDPA in LLM fine-tuning:
- Enhanced Efficiency: Reduce computational costs and improve model performance.
- Improved Focus: Prioritize essential information for better task performance.
- Parallelization and Speed: Achieve faster and more efficient computations.
- Scalability: Handle larger models and datasets effortlessly.
- Long-Range Dependencies: Model long-range dependencies with ease.
For more information, please refer to the detailed blog.
Experience enhanced performance by launching your fine-tuning job here.
Publish Date: 17-07-2024