
New Instruction Synthesizer API for generating structured datasets
Unlock the Future of Language Models with Our Revolutionary Instruction Synthesizer API! 🚀
We are excited to introduce the Instruction Synthesizer API, a powerful addition to our LLM Fine-tuning suite. This API allows developers to generate diverse, high-quality instruction datasets from raw, unstructured data, such as PDFs.
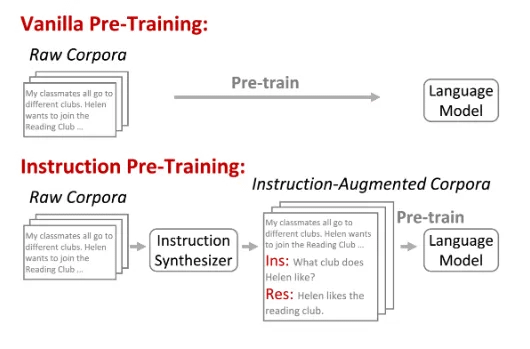
The Instruction Synthesizer API enables the creation of high-quality instruction-response datasets, allowing smaller models to achieve capabilities that can potentially surpass those of larger models.
Key Features
- Generalization to Unseen Data: Fine-tuned on specific tasks for enhanced relevance and accuracy.
- Scalability and Efficiency: Achieves performance comparable to larger models when fine-tuned on instruction-tuned datasets, even with smaller models like Llama3–8B.
Getting Started
Generate your own instruction-response datasets easily and cost-effectively with our API. For more information and to start using the API, click here.
For more details and guided implementation, refer to the blog.
Publish Date: 18-07-2024